BERT 분해하기! (2) Transformer 원리 ① - 인코더
BERT는 Transformer 구조의 인코더를 사용한 모델이다. 그렇다면 먼저 Transformer 가 어떠한 구조로 작동하는지 알아볼 필요가 있다. BERT를 공부하려면 인코더 부분만 알면 되지만, 공부를 위해 전체 구조를 다 알아보자. 일단 인코더부터 알아보자!
트랜스포머의 1) 데이터 흐름, 2) 인풋 데이터, 3) 각 레이어 순으로 모델을 분석해볼 것이다.
Transformer 데이터 흐름
1편에서 말했듯 Transformer는 번역 문제를 해결하고자 한다. 예를 들면 아래와 같은 input, target 시퀀스를 가지게 된다.
X = [‘Hello’, ‘,’, ‘how’, ‘are’, ‘you’, ‘?’] (Input sequence)
Y = [‘Hola’, ‘,’, ‘como’, ‘estas’, ‘?’] (Target sequence)
밑의 흐름도를 보며 데이터가 어떤식으로 모델에서 흐르는지 알아보자.
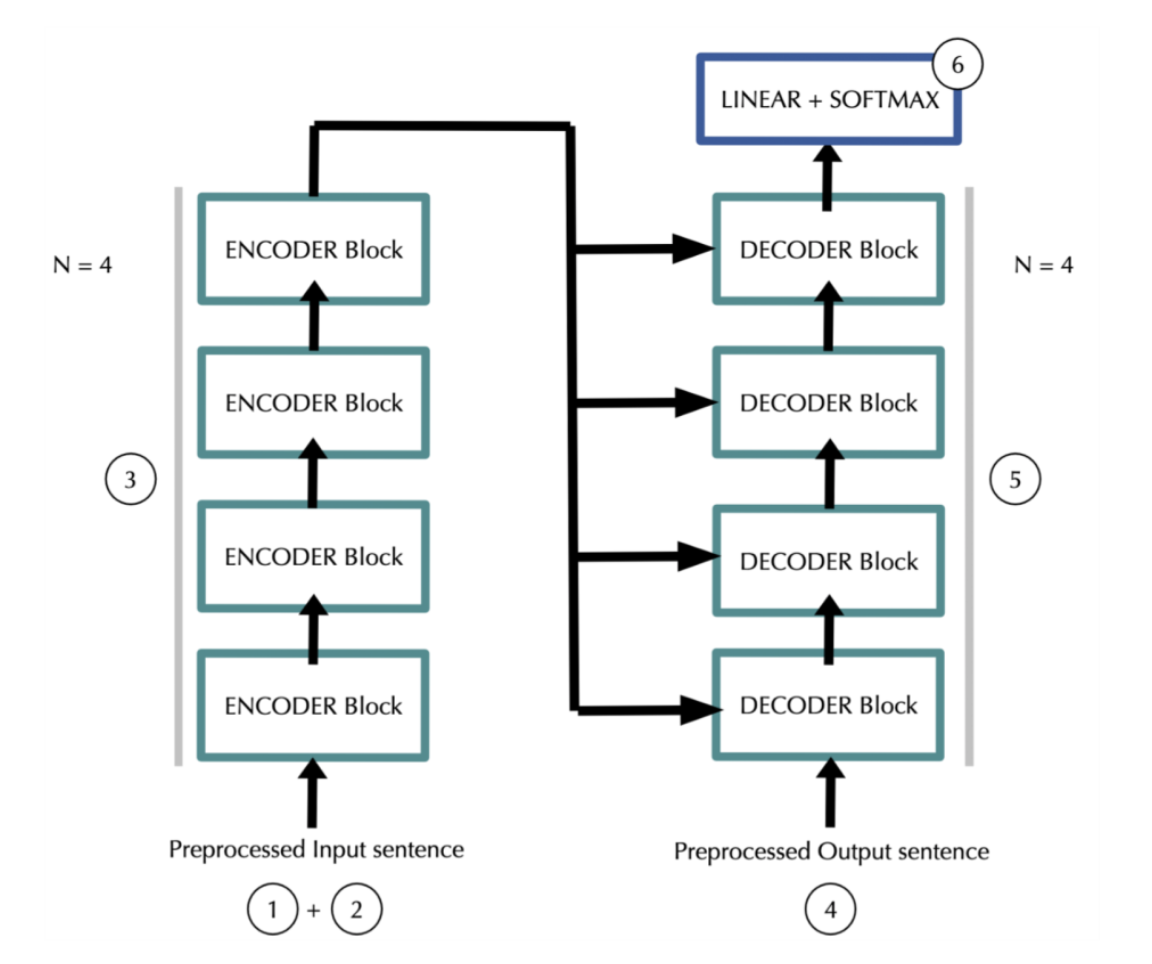
먼저 모델은 각 토큰을 embrace_dimb 차원의 벡터로 나타낸다. 그러면 우리는 input 시퀀스에 대해 input_length * emb_dim 차원의 매트릭스를 가지게 된다.
여기에 모델은 positional information(위치 정보) 를 더한다. 결과는 아까와 같이 input_length * emb_dim 차원이다.
데이터가 N개의 인코더 블록을 지난다. 결과는 여전히 input_length * emb_dim 차원이다.
target 시퀀스는 mask 되어서 디코더에서 1번 2번의 처리를 진행하게 된다. 결과는 targent_length * emb_dim 차원이다.
4번의 결과가 N개의 디코더 블록을 거친다. 각 반복에서 디코더는 인코더의 3번 아웃풋을 사용한다. 결과는 똑같이 targent_length * emb_dim 차원이다.
마지막으로 fully connected layer와 row-wise softmax를 거친다. 결과는 target_length * vocab_size 차원이다.
Inputs
input, target 문장을 매트릭스 형태로 어떻게 변환하는지 자세히 알아보자. 크게 1) 토큰 임베딩 2)포지션 인코딩의 두 가지 단계로 이를 수행할 수 있다.
토큰 임베딩
토큰 임베딩은 원래 RNN을 사용할 때 하는 방식과 같다. “Hello, how are you?” 라는 문장을 토큰 임베딩한다고 하면,
먼저 토큰으로 분리하고 ([“Hello”, “,” , “how”, “are”, “you”, “?”])
이를 숫자로 바꾼다. 각 토큰은 코퍼스 vocabulary 내의 unique한 정수값에 매핑된다. ([34,90,15,654,22,123])
각 단어들의 임베딩은 k차원의 벡터에 매핑되어 있다. 이 벡터의 요소들은 모델 파라미터로 여겨져서 훈련시 업데이트 된다.
예를 들어 위에서 34는 E[34] = [123.4, 0.32, …, 94.32] 이런식으로 임베딩에서 벡터값을 가져올 수 있다. 이렇게 각 단어들의 임베딩을 가져와서 쌓으면 input_length * emb_dim의 매트릭스를 얻을 수 있다.

(+ target 문장은 앞에
포지션 인코딩
현재까지의 representation은 같은 단어가 시퀀스의 다른 위치에 등장할 때의 차이를 인코딩하지 못하고 있어 위치 정보를 추가적으로 인코딩해주어야한다. Transformer는 포지션 인코딩을 위해 다음과 같은 함수를 사용한다.
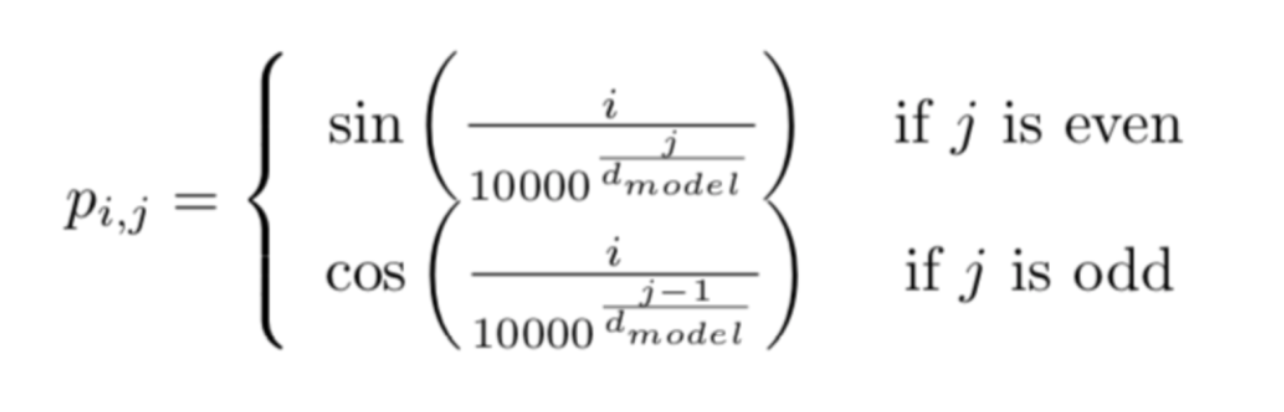
전체 예시의 P는 다음과 같을 것이다.
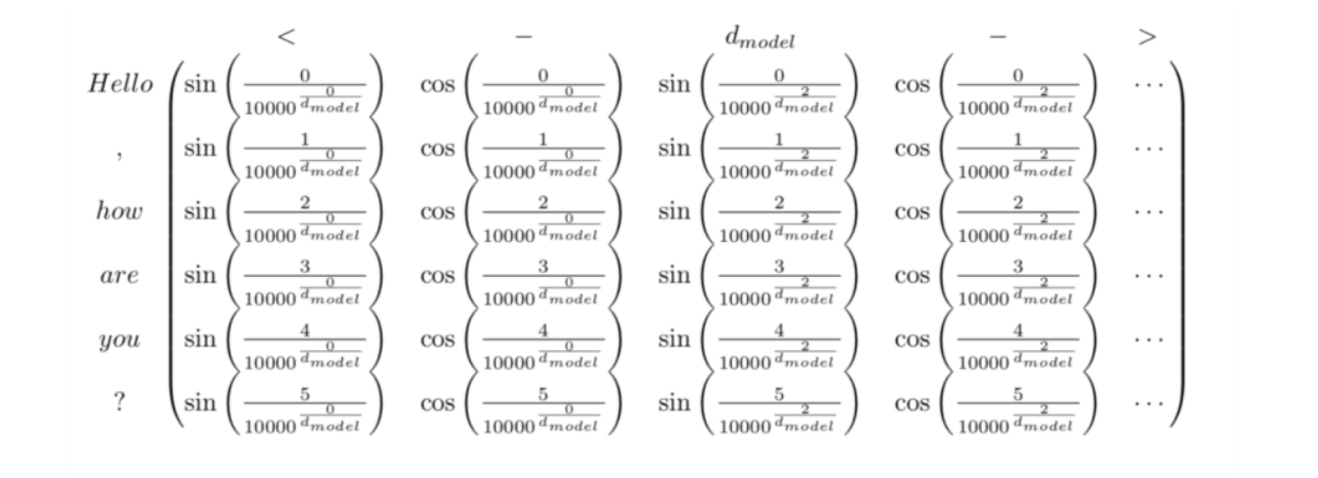
이렇게 인코딩된 위치 정보는 원래의 매트릭스에 더해진다.
Layers
Encoder Block
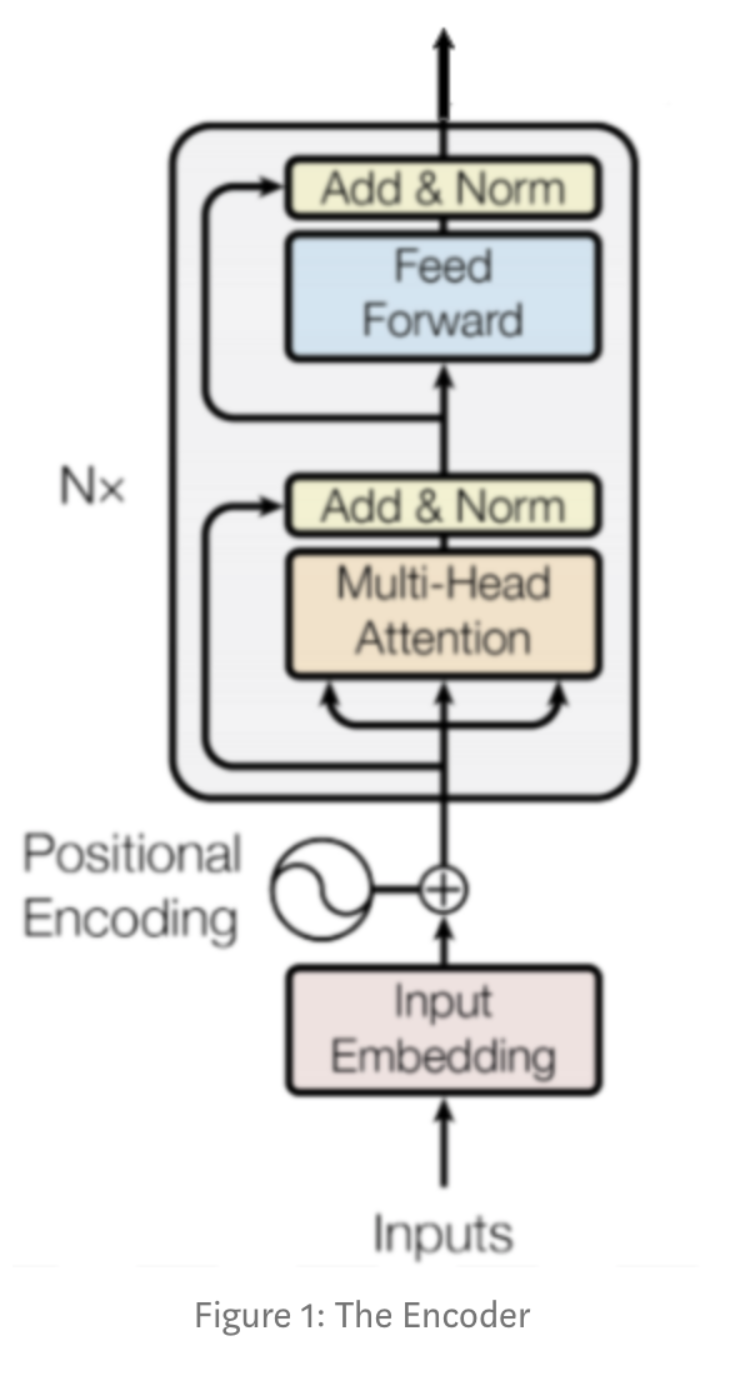
각 레이어를 세세히 살펴보기 전에 먼저 전체 인코더 구조는 위와 같다. 위와 같은 인코더 블록들이 N개 연결되어 인코더의 결과를 낸다. 특정 블록은 인풋의 vectorial representation 사이의 관계를 찾아내는 역할을 하고 아웃풋에 이를 인코딩한다. 이 프로세스를 반복하며 신경망이 단어들 사이에 더 복잡한 관계들을 capture하게 되는 것이다. 이제 각 레이어들의 역할을 알아보자.
① Multi-Head Attention
Transformer는 Multi-Head Attention을 사용하는데, 이는 attention을 다른 weight 매트릭스들을 사용해 h번 계산하고 이를 concatenate한다는 뜻이다. 각각의 Scaled Dot-Product Attention의 병렬 계산을 head라고 부른다.
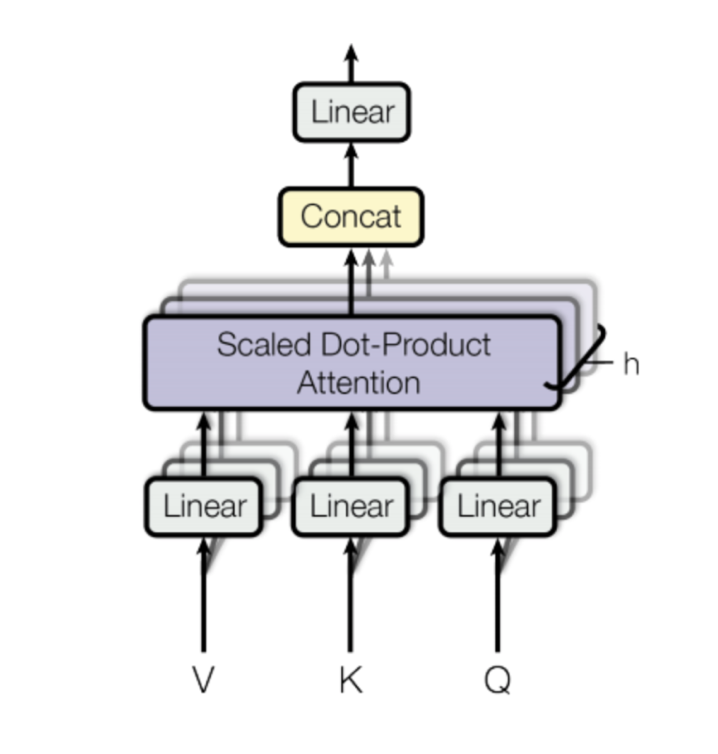
위 그림과 같이 모든 헤드는(보라색 부분) 계산 후 concatenate된다. concatenate 된 결과는 input_length * (hd_v)가 되고, linear layer가 오는데 이는 (hd_v) * (emb_dim) 의 형태이므로 최종 결과는 input_length * emb_dim 이 된다.
head를 어떻게 계산하는지 자세히 알아보자.
 위의 첫번째 식을 먼저 살펴보자. 각 head는 3개의 다른 projection을 attention 한 결과이다 (subscript i 는 특정 헤드를 나타낸다). 최종 결과는 앞서 설명했듯 이러한 head들을 concatenate 한 후 linear layer를 거쳐 나온 결과이다.
위의 첫번째 식을 먼저 살펴보자. 각 head는 3개의 다른 projection을 attention 한 결과이다 (subscript i 는 특정 헤드를 나타낸다). 최종 결과는 앞서 설명했듯 이러한 head들을 concatenate 한 후 linear layer를 거쳐 나온 결과이다.
밑의 식을 통해 head의 계산을 더 자세히 살펴보자. 이 식에서 X는 인풋 매트릭스이고, W 는 각 weight 매트릭스이다. 이렇게 input을 각가의 weight 매트릭스에 project해서 K,Q,V를 구하게 된다. 이 값들을 사용해 Dot-Product Attention을 구하게 되는데 식은 다음과 같다.
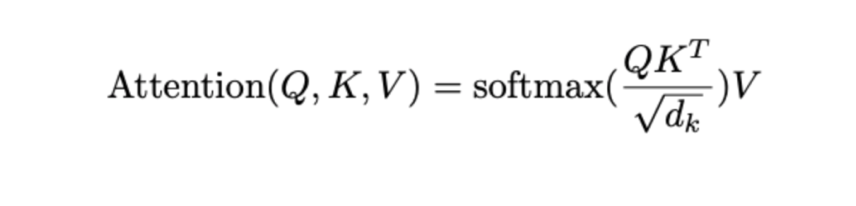
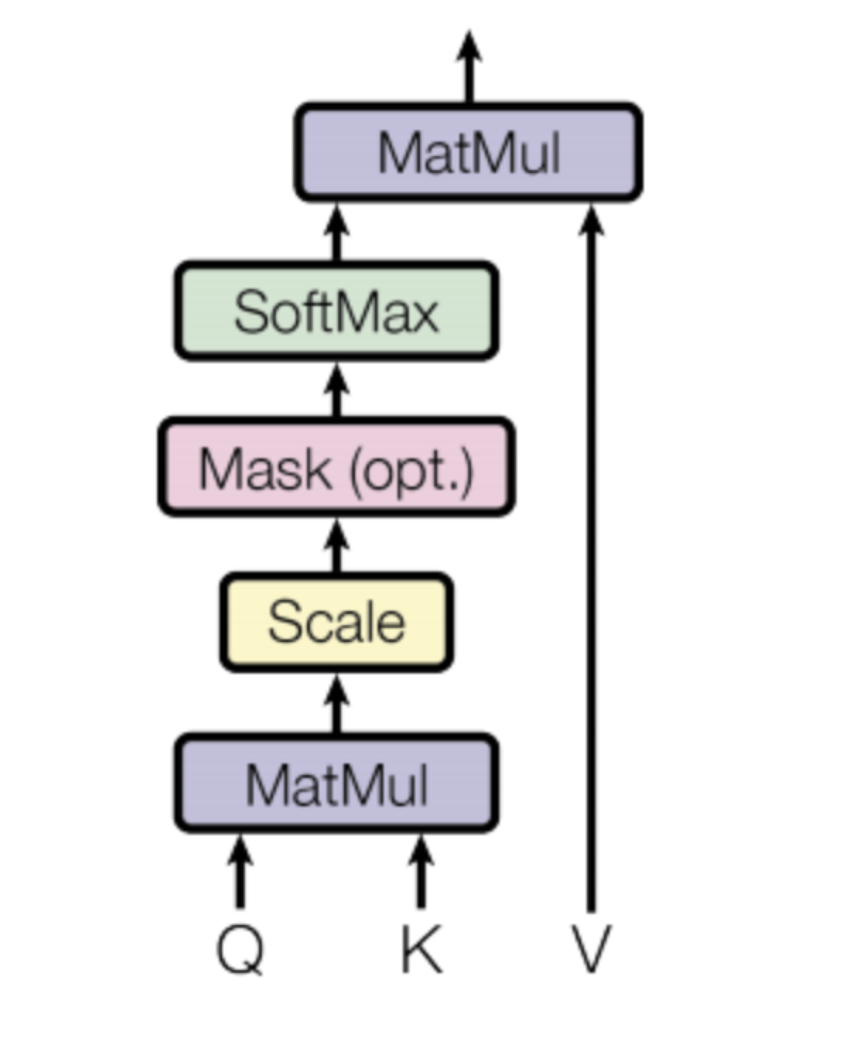
Attention 연산을 한다는 것은 알겠는데 과연 attention 연산이 무엇을 하는걸까? 식을 하나씩 살펴보면서 원리를 이해해보자.
먼저 Q,K(transposed) 부터 보자. Q,K는 토큰에 대한 두 가지의 다른 projection이다. 이들의 dot product는 두 projection 사이의 유사도를 측정하는 것이라고 볼 수 있다(자세한 내용은 https://math.stackexchange.com/questions/689022/how-does-the-dot-product-determine-similarity 링크를 참고하자). 이렇게 나온 결과는 인풋 sequence의 각각의 토큰 사이의 관계를 나타낸다고 볼 수 있다.
앞에서 나온 결과는 d_k의 제곱근으로 나누고 이 결과에 소프트맥스 함수를 적용하게 된다. 소프트맥스를 쓰면 결과는 0에서 1 사이가 되고 각 행의 합은 1이 된다. 최종적으로는 여기에 V를 곱하게 된다.
이렇게 식만 보면 무슨 말인지 잘 이해가 안가니 실제 예시를 살펴보자.
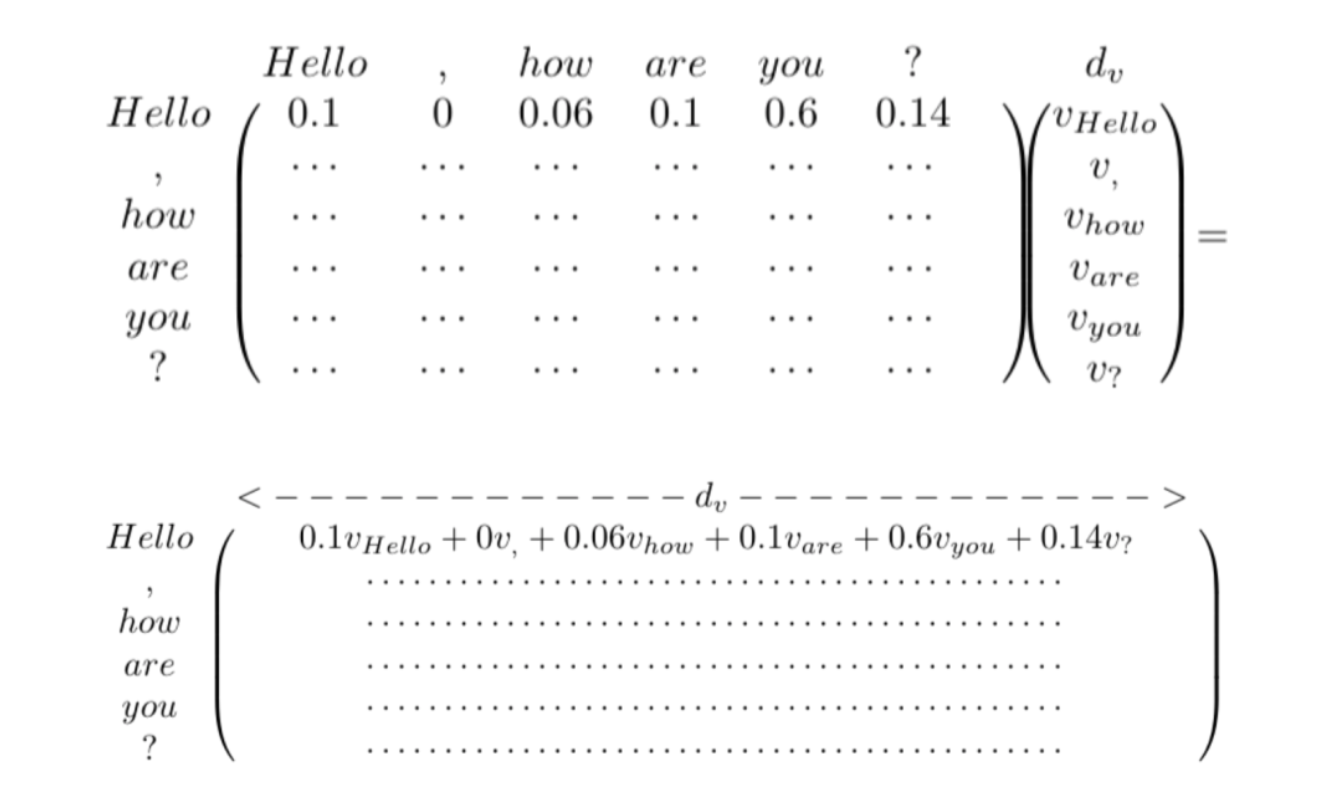
소프트맥스까지 거친 결과가 [0.1, 0, 0.06, 0.1, 0.6, 0.14] 라고 나왔다고 치자. 여기에 V를 곱하게 되면 결과는 아래와 같이 나온다. Hello 라는 단어가 여러 다른 단어들에 의해 표현되는 것이다. 여기에 나머지 다른 헤드들까지 계산이 되면 Hello라는 단어는 다른 단어에 의한 표현을 concatenate한 결과가 될 것이다. 인풋 토큰 사이의 h개의 다른 관계를 배우게 되는 것이다. 결국 네트워크는 훈련을 거치며 토큰 간 관계를 배우게 된다.
② Position-wise Feed-Forward Network
multi-head attention 다음에 오는 이 부분은 다음과 같은 과정을 거친다.
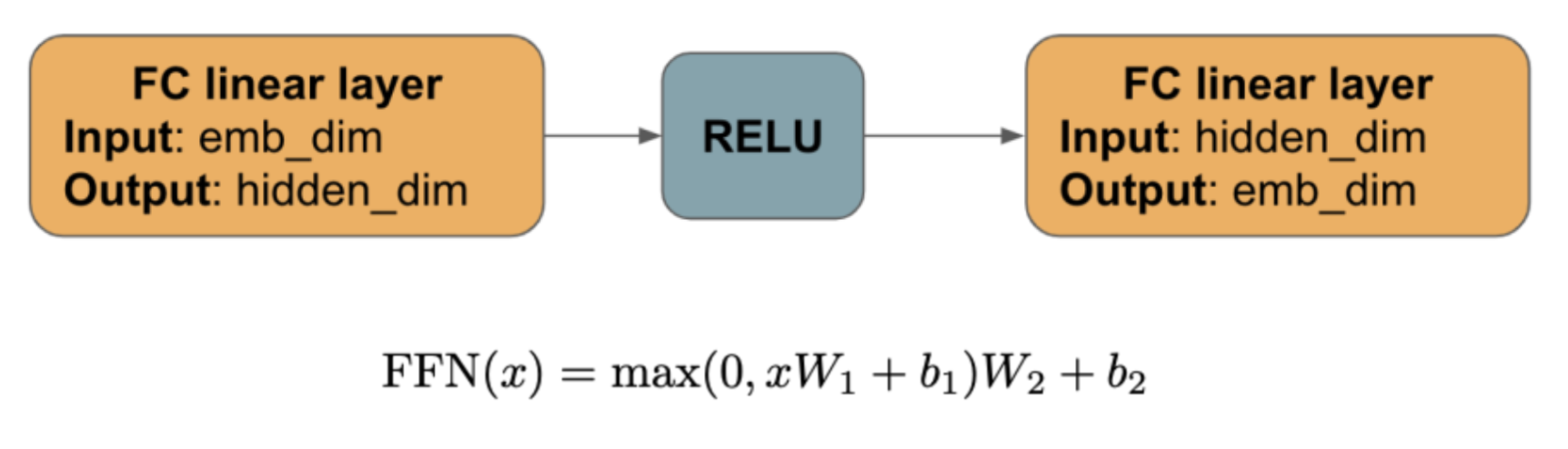
여기서 각 토큰의 벡터 representation들은 서로 interact하지 않는다. 최종 output은 input_length * emb_dim 의 형태이다.
③ Dropout, Add & Norm
Multi-Head Attention과 Feed Forward 레이어는 모두 인풋과 아웃풋이 같은 dimension이다. 이들을 Sublayer라고 하고 인풋을 x라고 할 때 각 Sublayer 다음에 dropout이 0.1 확률로 적용되고 sublayer의 인풋에 더해진다.
dropout은 알다싶이 오버피팅을 줄이기 위해 forward pass를 할 때 전체 weight 중 일부만 참여시키고 나머지를 0으로 만드는 방법이다. 쉽게 생각하면 너무 많은 feature들을 다 고려하다보면 사공이 많으면 배가 산으로 가는 것과 같이 오버피팅이 된 결과가 나올 수 있는 것이다.
Multi-Head Attention에서 이것은 원래 토큰의 representation을 다른 토큰들과의 관계에 기반한 토큰 representation에 더한다는 의미이다. 이를 통해 토큰은 다른 토큰과의 관계 + 토큰 그 자체의 의미를 둘 다 배우게 된다.
마지막으로 토큰별(행별)로 평균과 표준편차를 사용한 정규화 과정을 거쳐 더 안정적인 모델을 만든다.
다음 글에서는 디코더 구조를 알아볼 것이다!
출처
https://medium.com/@mromerocalvo/dissecting-bert-part1-6dcf5360b07f