BERT 분해하기! (3) Transformer 원리 ② - 디코더
BERT에는 트랜스포머의 인코더만 쓰이지만 우리는 공부를 위해 디코더 부분도 살펴보자.
아니 인코더 설명도 엄청 길었는데 디코더는 또 언제 배워… 하고 이 글을 나가지 말았으면 좋겠다😂 다행히도 인코더랑 겹치는 부분이 많아서 금방 이해할 수 있다.
이번에도 1) 인풋 데이터, 2) 각 레이어 순으로 분석해보자.
앞서 인코더를 설명할 때 말했듯 트랜스포머가 해결하고자하는 문제는 번역이다. 우리 모델은 인풋 문장 안 단어들의 관계도 알아야하고, 인풋 문장의 정보와 각 단계에서 이미 번역된 단어들의 정보를 합쳐서 생각할 줄도 알아야한다. 인풋 문장 안 단어들의 관계는 인코더에서 파악한다. 그렇게 파악된 인풋 문장의 정보를 디코더에서 타겟 문장의 정보와 합하는 것이다.
Inputs
1편에서 인풋 문장이 인코딩되었듯, 타겟 문장도 똑같이 인코딩된다. 각 토큰을 임베딩화하고 포지션 인코딩을 더한다. 한 가지 다른 점은 타겟 문장에는 맨 앞에
Layers
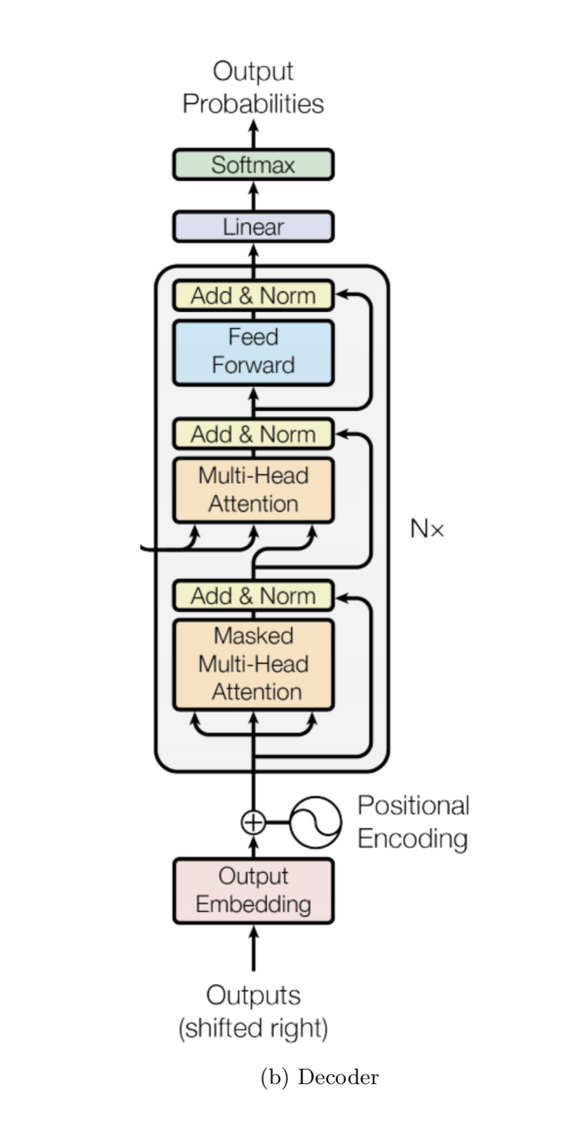
잠시 각 레이어들을 살펴보기 전에 디코더가 train/test 상황에서 어떻게 다르게 쓰이는지 알아보자.
[ TEST ]
테스트 상황에서는 답을 모르므로 다음과 같은 과정을 거친다.
- 인풋 문장의 embedding representation 계산
-
을 첫 타켓 시퀀스로 사용하면 모델이 다음 토큰을 아웃풋으로 내놓음 - 아웃풋으로 내놓은 토큰을 타겟 시퀀스에 더해서 새 prediction을 만듦
- 시퀀스 끝을 나타내는
토큰을 예측 결과로 내놓을 때까지 3번 반복
요약하자면
[ TRAIN ]
훈련 상황은 우리가 답을 가지고 있으므로 약간 다르다. 이 때는
그런데 생각해보면 모델이 인풋의 토큰을 보고 다음 토큰을 예측할 수도 있다. como 다음에 estas가 오는 걸 보고 estas를 추측 결과로 내놓는 것이다. 이러면
모델은 현재 단어 오른쪽에 있는 정보는 보면 안되지만 이미 예측한 단어들은 볼 수 있어야한다.

인풋을 다음과 같은 매트릭스로 표현했을 때 estas를 추측하기 위해서는 초록색 부분의 정보만 사용하고 빨간 부분의 정보를 쓰면 안된다. linear layer는 row-wise계산을 하므로 문제가 없지만 Multi-Head Attention을 할 때는 인풋을 mask해줘야한다.
training을 할 때는 모든 행의 prediction이 중요하지만 반복작업이므로 우리는 마지막 prediction을 통해 다음 토큰을 예측하는 과정을 중점적으로 살펴보자.
① Masked Multi-Head Attention
자 이제 레이어를 살펴보자. 먼저 Masked Multi-Head Attention은 MultI-Head Attention 과 같은데 인풋을 masking한다는 것만 다르다. 각 디코더 블록의 첫번째 블록만 이렇게 마스킹을 해주면 되는데 중간에 들어간 Multi-Head Attention은 인코딩 블록의 결과와 디코딩 블록의 그 전 레이어들의 아웃풋 결과를 합치기 때문이다(다 test time에도 제공되는 정보이다).
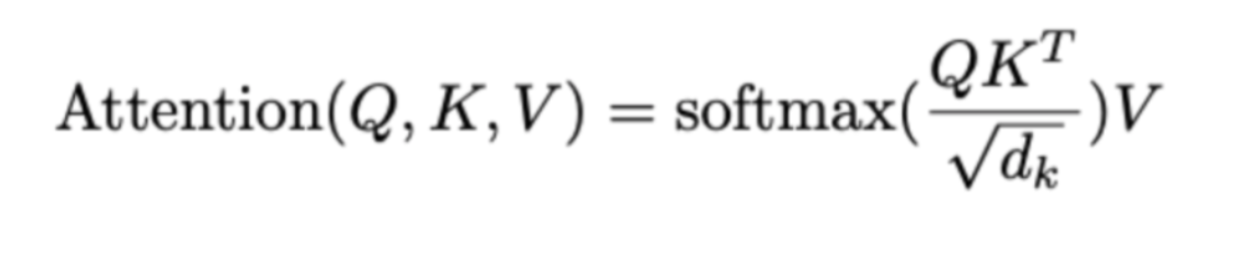
1편에서 Multi-Head Attention을 설명할 때 이 식을 봤을 것이다. 마스킹은 이 중에서 소프트맥스 안에 있는 부분의 계산 다음에 일어난다. 마스킹 작업은 다음과 같이 한다. 왼쪽에서 오른쪽처럼 -무한대로 오른쪽 위 삼각형 부분을 바꿔주는 것이다.

여기에 적힌 각 숫자들이 행별로 상대적인 attention 측정치라는 것을 생각하면 숫자가 클수록 그 토큰에 더 attention을 줘야한다는 의미이다. 그래서 이를 -무한대로 바꿔주는 것은 그 토큰을 무시하겠다는 것과 같은 의미이다. softmax를 거치면 이 값은 0으로 변하고 V와 곱할 때 이 토큰들은 무시되는 것이다.
나머지 계산은 Multi-Head Attention과 같다.
② Multi-Head Attention
중간에 들어가는 Multi-Head Attention 의 인풋은 앞서 살펴본 Multi-Head Attention 레이어들과 조금 다르다. 여기서는 인코더의 아웃풋 E와 디코더의 이전 레이어의 아웃풋인 D를 사용한다.
E 는 input_len * emb_dim, D는 target_len * emb_dim 형태이다. 이들을 사용해 attention을 계산할 때 이전처럼 세 개의 weighted matrice를 사용하는데 이번에는 인풋 X가 아닌 D,E를 다음과 같이 사용한다.

다른 계산은 인코더의 Multi-Head Attention과 같다. 이 때 소프트맥스를 거친 결과값은 인코딩된 인풋 토큰과 인코딩된 타겟 토큰 사이의 관계를 표현하고 target_length * input_length 의 형태이다. 
이는 여러 헤드에 반복되기 때문에 타겟 시퀀스의 각 토큰은 인풋 시퀀스 토큰들과의 관계 여러개로 표현될 것이다.
③ Linear and Softmax
예측된 토큰을 내놓기 전의 마지막 단계이다. 마지막 Add, Norm을 거친 결과인 target_len * emb_dim 형태를 인풋으로 받는고 다음 계산을 한다.
xW_1
x는 위의 인풋의 각 행이고, W_1은 emb_dim * vocal_size의 weight 매트릭스이다. 그러므로 둘을 곱한 결과는 각 행별로 vocab_size만큼의 벡터이다. 마지막으로 이 벡터 별로 소프트맥스가 적용되어 각 vocab속 단어별로 다음 토큰이 될 확률을 구하게 된다.
이제 다 배웠다!
밑에 전체 트랜스포머 모델을 보면서 지금까지 배운것을 각자 다시 한번 복습해보자. 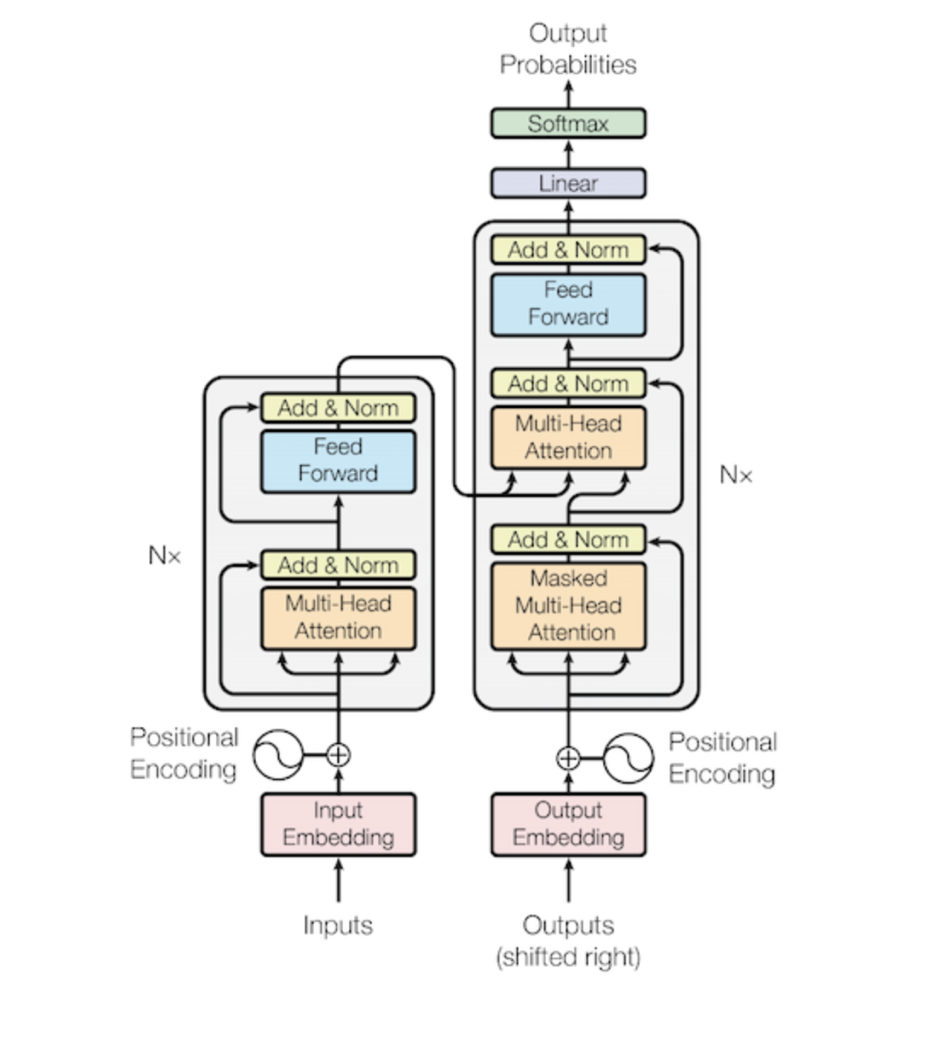
이제 트랜스포머의 이론은 끝이다! 👏👏👏 다음 글에는 트랜스포머의 실제 pytorch 구현을 함께 알아보자.
출처
https://medium.com/@mromerocalvo/dissecting-bert-part1-6dcf5360b07f